실습은 주피터로 하였고, kpc의 DSAC Module1 DATA Programming을 참고했습니다.
지난 시간에 간단하게 DataFrame과 Series가 무엇인지 알아보았으니 이번에는 문법 위주로!

numpy와 pandas를 불러와주고 추가로 DataFrame, Series를 불러와준다.
- Series 인덱스 정렬하기
Series는 파이썬의 딕셔너리와 형태가 유사하다.
Series(values 값, index = index 값)으로 표현할 수 있다.

sort_index()를 이용하여 인덱스를 기준으로 정렬하였다.
하지만! 원본 데이터는 변하지 않는다.

원본 데이터도 변경하고 싶다면, sort_index()의 속성 값으로 inplace=True를 추가해주면 된다.

- 행, 열 정렬하기

우선 0부터 11까지의 수를 3행 4열로 나타냈다. index와 columns의 이름은 순서를 무작위로 작성했는데, 이를 정렬해볼 것이다.

위에서 배운 sort_index()를 이용해서 행 정렬을 해주었다. 알파벳 순으로 정렬되었다.

열 정렬을 하기 위해 axis = 1을 추가하였다. 정렬 축이 행에서 열로 바뀌었다.
sort_columns()라는 함수는 없다!! 열 정렬을 하기 위해서는 sort_index(axis=1)인 거 기억해두기

ascending=False를 추가하면 index가 내림차순으로 정렬된다.
-sort_values()로 columns 값 기준 정렬하기
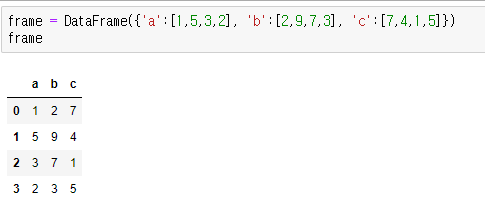
위 예제의 DataFrame 형식과 다른 걸 알 수 있다. 딕셔너리 형태로 DataFrame을 만들어주었다.

frame.sort_values(by='c')를 하게 되면 c에 있던 값들이 오름차순으로 정렬된다.
파이썬에서 딕셔너리의 형태는 {key:value} 형태이다. 이와 유사하게 데이터 프레임에서 c(key)의 values를 정렬한다고 생각하면 된다.
- Series에서 순위 매기기

Series에서 rank()를 사용해서 순위를 정하고 순위 값을 배정할 수 있다. 기본은 오름차순이다.
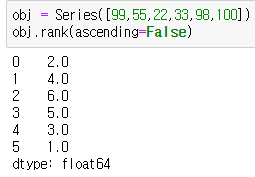
ascending=False를 추가해 내림차순으로 순위를 매겼다.
내림차순 정렬이 아니라 내림차순으로 순위를 매기는 거 주의!!
- 만약 동점이 있다면??


동점의 순위 값으로 중간 평균값을 주게 된다.
- 동점이 존재할 경우 먼저 나타나는 값에 높은 순위를 주고 싶다면??

method='first'를 추가하면 나타나는 순서에 따라서 순위가 주어진 것을 알 수 있다.
- DataFrame 합, 평균값 구하기

열을 기준으로 합이나 평균을 구한다.
Series도 가능하다.

frame에 NaN이 있는데 합계에 반영하고 싶다면?
frame.sum()을 하게 되면 NaN을 무시하고 합을 구하게 된다.

NaN을 반영하고 싶다면 skipna를 사용하면 된다.
skipna는 skip NaN을 뜻한다.

'IT > Python' 카테고리의 다른 글
| [파이썬] 이터레이터 이터러블 차이 쉽게 이해하기 (0) | 2025.01.11 |
|---|---|
| [장고] SSL 인증서 구매, runsslserver로 적용 (0) | 2022.05.04 |
| [DSAC M1] Pandas(판다스) - DataFrame, Series 기본 개념 (0) | 2021.08.17 |
| [DSAC M1] NumPy(넘파이) (0) | 2021.08.17 |
| [DSAC M1] randn, rand, randint 차이 / matplotlib (0) | 2021.08.16 |

